

Step 4: Learning more about a target gene on an NCBI Gene Page
Background
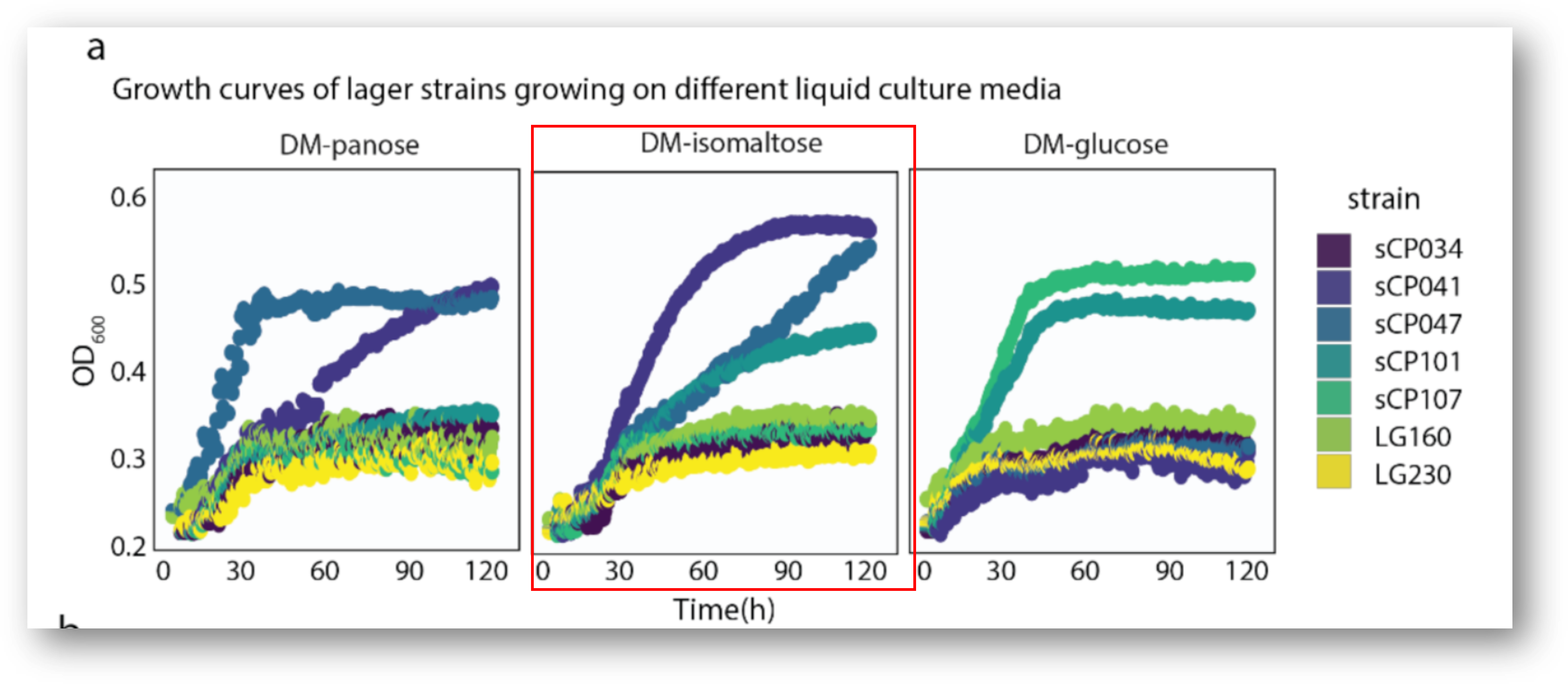
Figure 2a (Loza et al. 2021): Different genotypes of lager yeast have different abilities to grow on different types of sugar.
The IMA1 Gene
For our gene level analyses, we are going to be focusing on the IMA1 gene, which is part of a family of isomaltase enzymes, required for the digestion of isomaltose (a dissacharide). Isomaltose is one of a number of carbohydrates present in beer wort or bread flour that are not digestible by all yeast strains, including some lager-producing yeasts. This effects things like alcohol level and flavor profile of the final product, so industrial brewers and bakers are interested in finding or engineering strains of yeast that use these sugars efficiently. Check out Loza et al. 2021 for more background on an effort to improve sugar usage in S. pastorianus!
Task: Find gene and gene product Information for IMA1 on NCBI
The NCBI Gene database aggregates gene-specific information and connections such as genomic location sequence, expression, structure, function, citation, and homology data, all into one report per gene. Given the aforementioned variation in ability to digest isomaltose in different yeast strains, we want to investigate genetic variation in the IMA1 gene/protein sequence in different yeast strains. Our objective in this exercise is to find the the entry in the NCBI Gene database for the S. cerevisiae IMA1 gene and use it to locate a reference protein sequence for the gene.
Searching for a Specific Gene in the NCBI Gene Database
Let's start by navigating to the landing page for the NCBI Gene Database , where we will search for the IMA1 gene in S. cerevisiae. Maybe you don't remember exact syntax for doing so, so you try the following: "Saccharomyces cerevisiae IMA1"

You can see that one result in particular meets our criteria for the S. cerevisiae IMA1 gene page. Clicking on either of the IMA1 links pointed out below will take you to the NCBI Gene Page for the S. cerevisiae IMA1 gene. 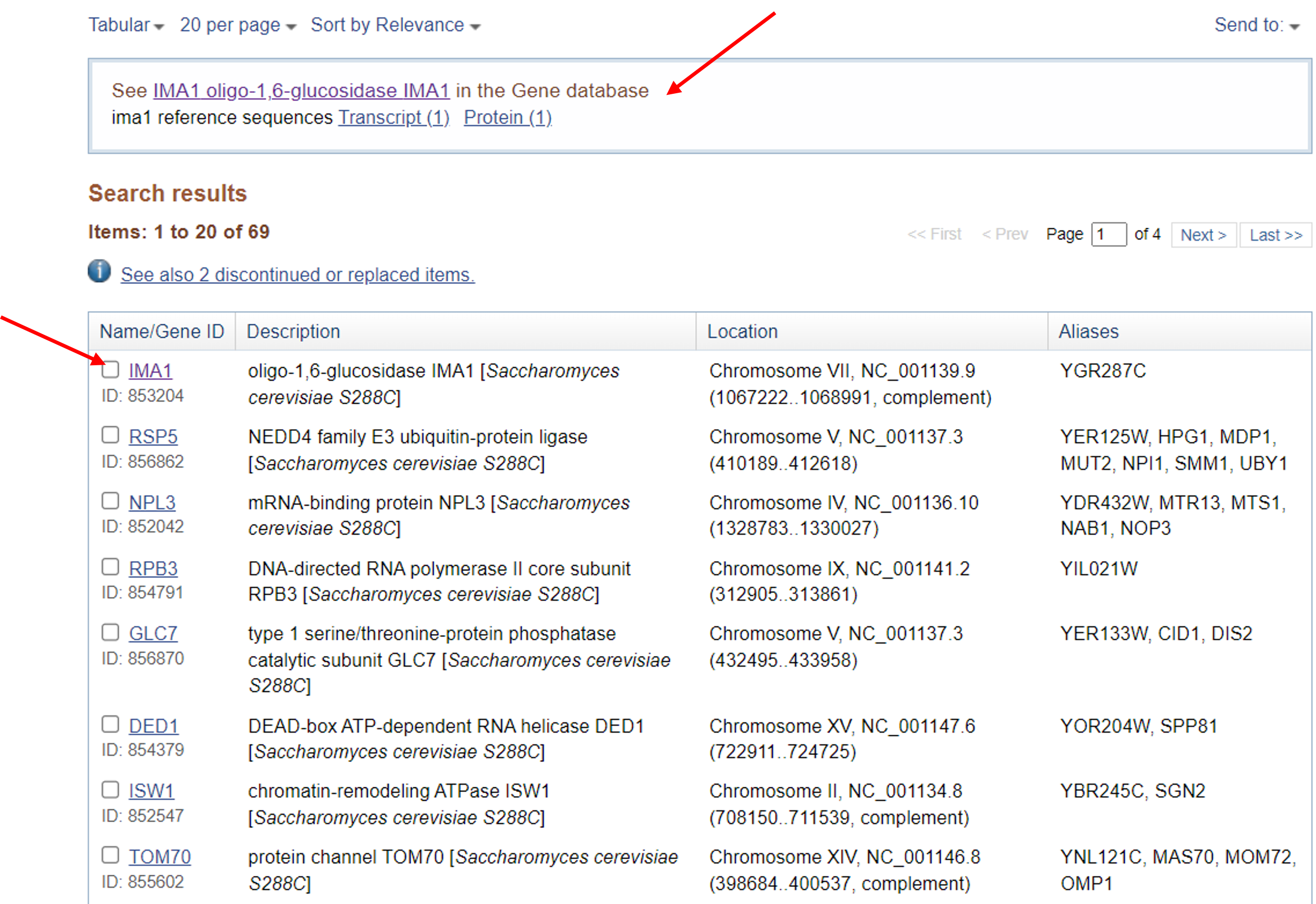
Gene Summary and Download Options
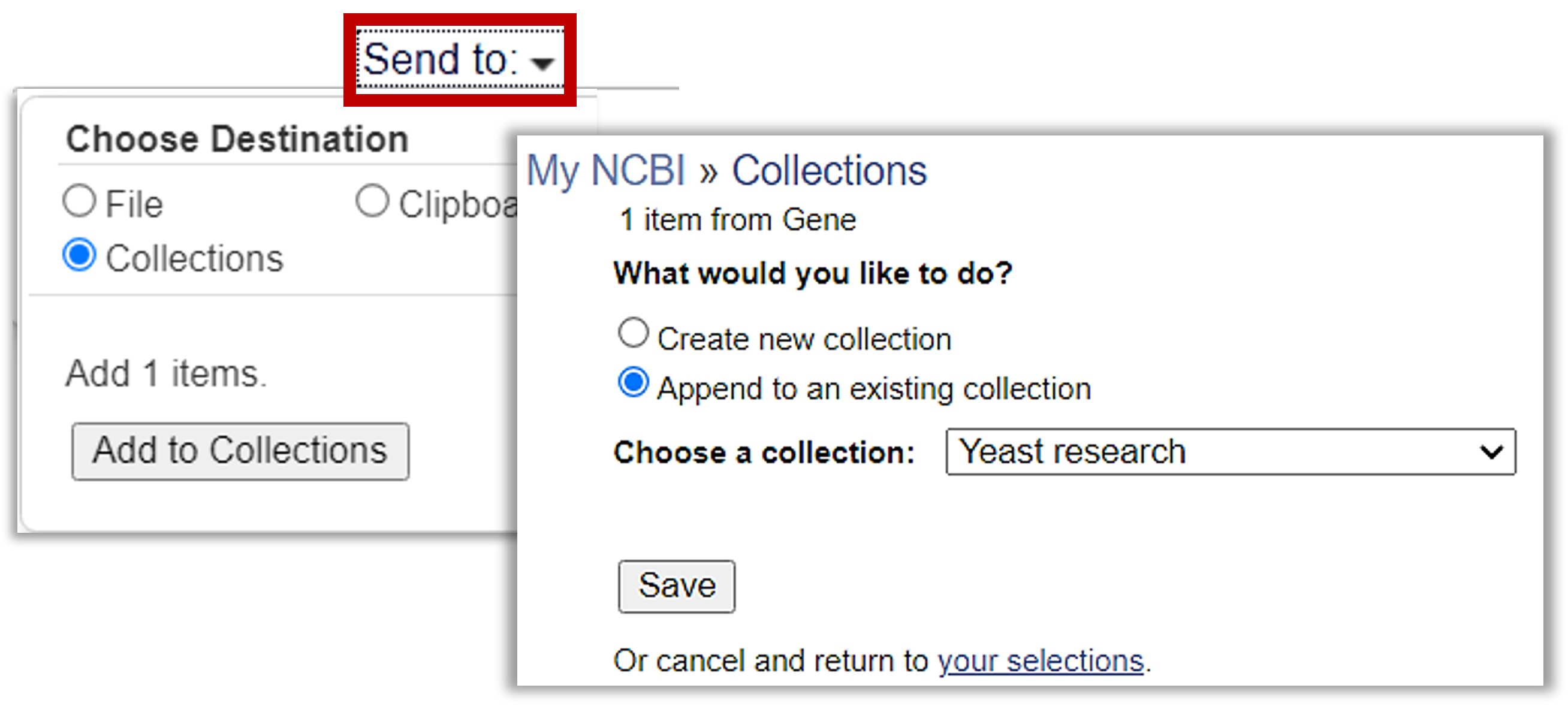
Before anything else, make sure to save this page to your Yeast Research Collection!
Save the Gene to the Yeast research folder!
1. Click "Send to" to add to the existing Yeast research folder.
  |
Before scrolling down the loooooong NCBI Gene Page, pause and take a look at the top Summary section, as there are a lot of helpful links and options. 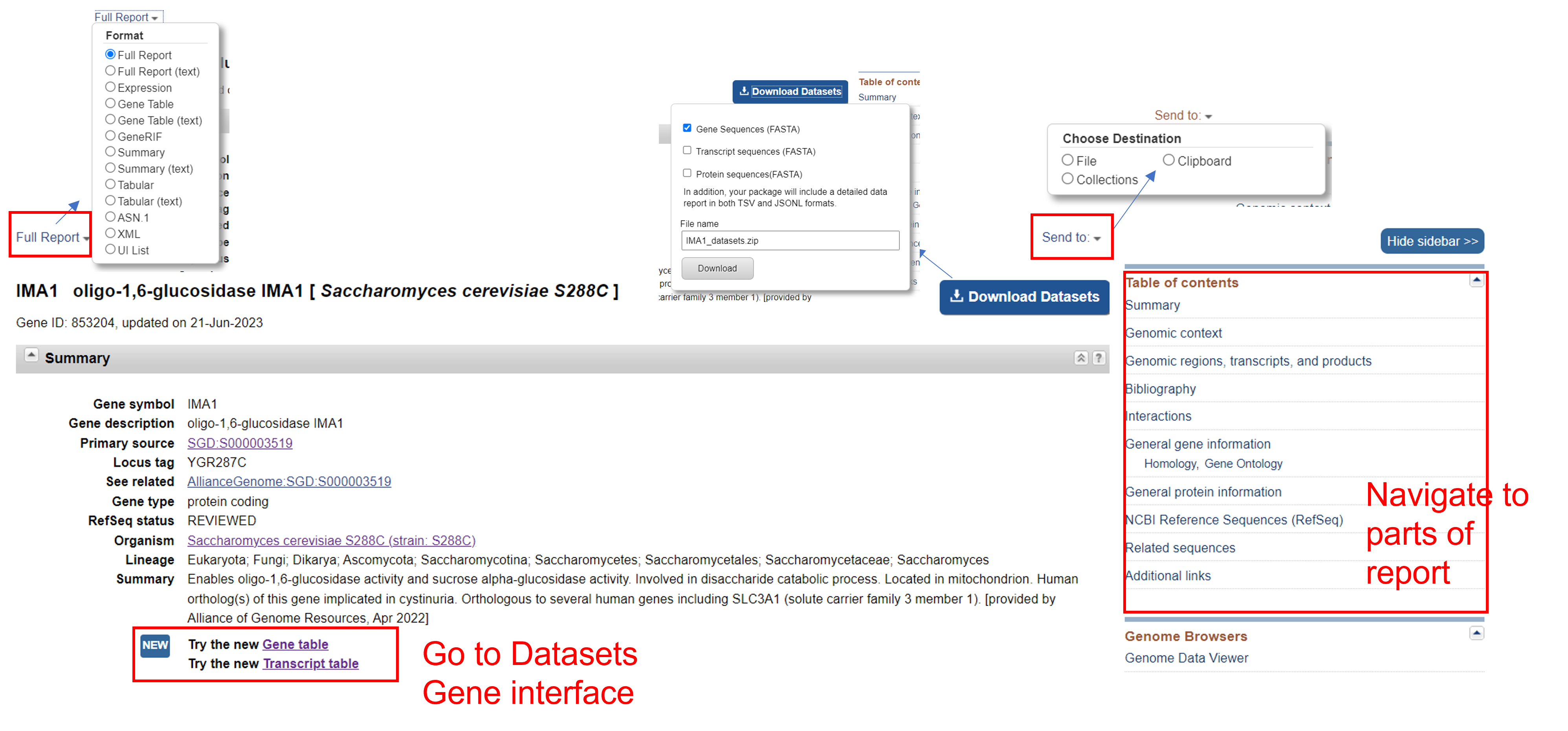
In words:
- Full Report: Download information contained in the Gene Page onto your local computer in a wide variety of formats.
- Send To: Save this page to a Collection
- Table of contents: Allows you to jump to particular sections of this looooong report.
- Download Datasets (advanced): Directly download the actual sequence data related to this Gene Record.
Looking at the summary in more detail: 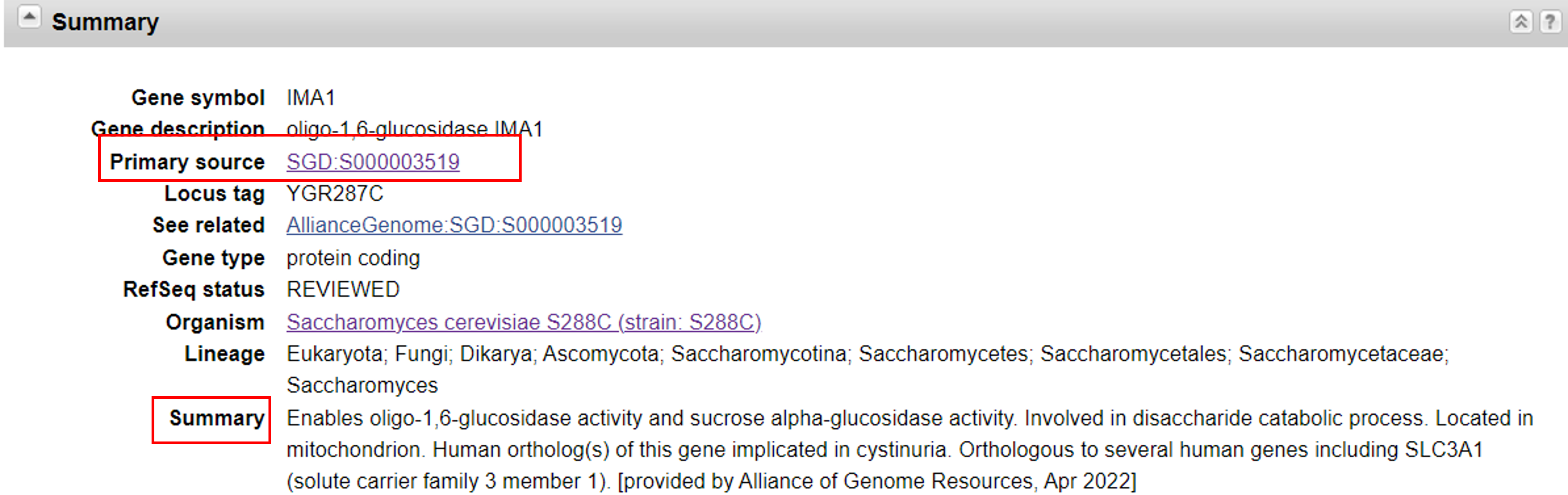
There are two pieces of particularly interesting information:
- Primary source for the information, sometimes it is an external database. In this case, it is the Saccharomyces Genome Database https://www.yeastgenome.org/
- The actual summary text, which gives you more context about this gene, such as the fact that there is an ortholog of IMA1 in humans.
NCBI RefSeq Sequences
This section describes the gene-specific NCBI reference sequences (RefSeqs) that have been established for this gene. As a reminder, RefSeqs are the well-annotated, non-redundant set of reference sequences, so we will want to move forward with the sequences we find in this section. The section highlighted below specifically provides gene and protein sequences associated with the reference genome assembly for S. cereivisiae. 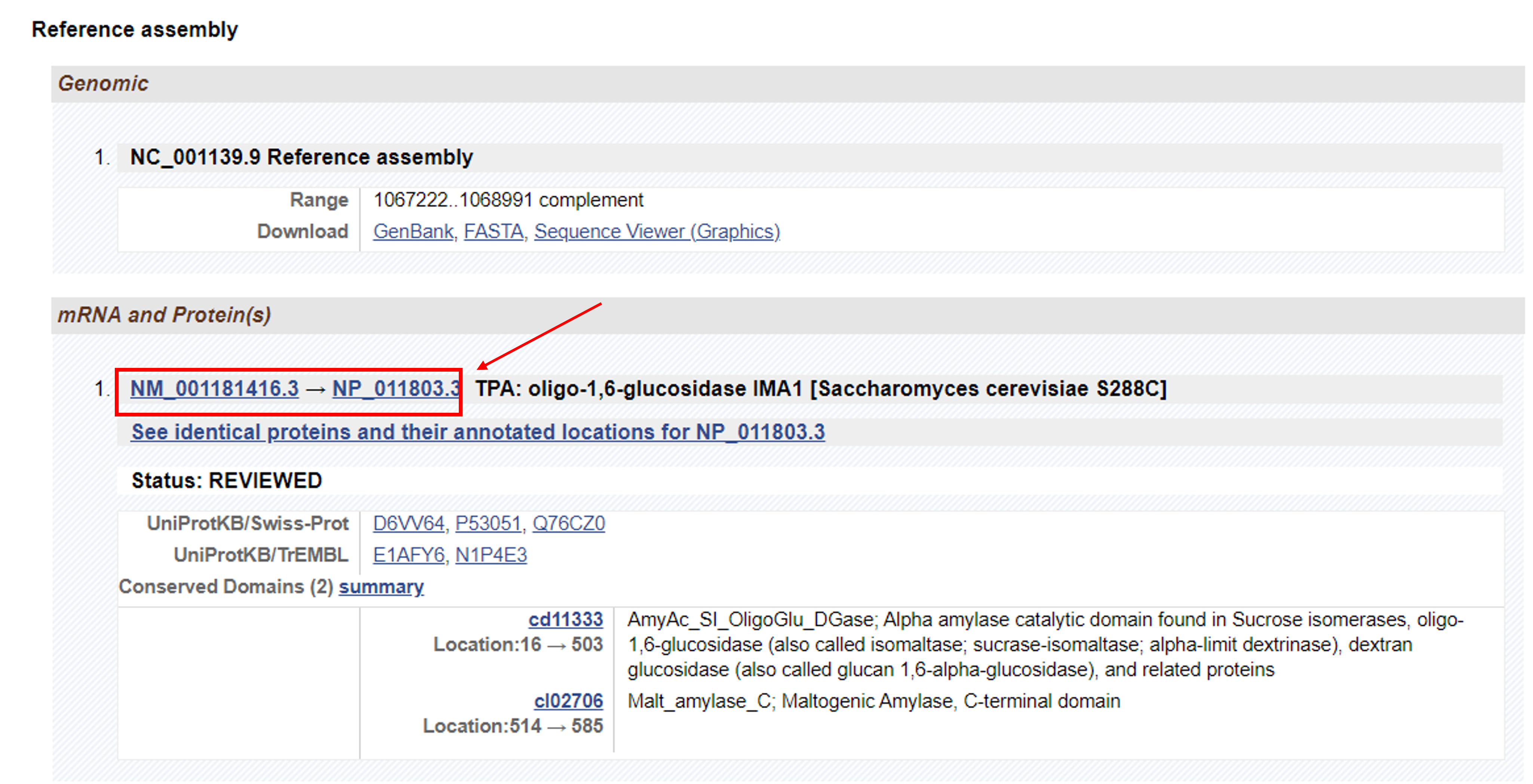
Because we are ultimately looking for the RefSeq protein sequence, we can focus on info under the mRNAs and Proteins header. There are two important pieces of important information to extract here:
- NM_001181416.3: Accession number and link to the RefSeq mRNA sequence record associated with this gene, in the NCBI Nucleotide database.
- NP_011803.3: Acccession number and link to the RefSeq Protein sequence record in the NCBI Protein database. Clicking the link will take you where we need to go!
In the future, you can jump directly to a link to the RefSeq Protein record by looking in the "Related Information" Section of the sidebar: Since we just want the non-redundant RefSeq Protein record, make sure to click RefSeq Proteins. Clicking just Proteins, will take you to a list of ALL related entries in the Protein databases, which may contain redundancy, but could be useful for other applications.
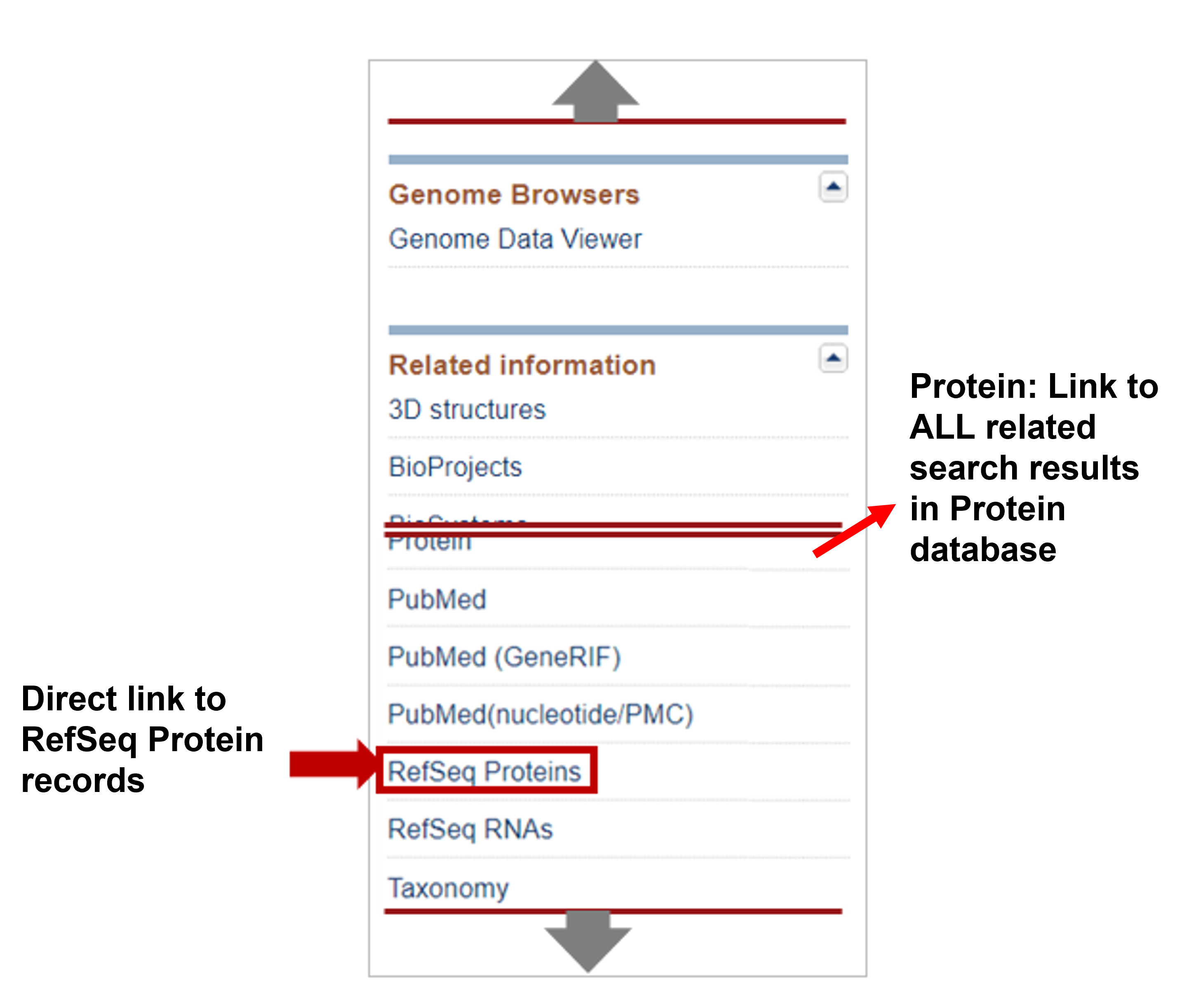
Use either method above to navigate to the RefSeq Protein associated with the S. cervisiae IMA1 gene!
NCBI Protein Record for IMA1
By now, you should be on the RefSeq Protein Record page for S. cerevisiae, found under accession number NP_011803.3. This is a great time to use Send To -> Yeast Research collection to save this record!
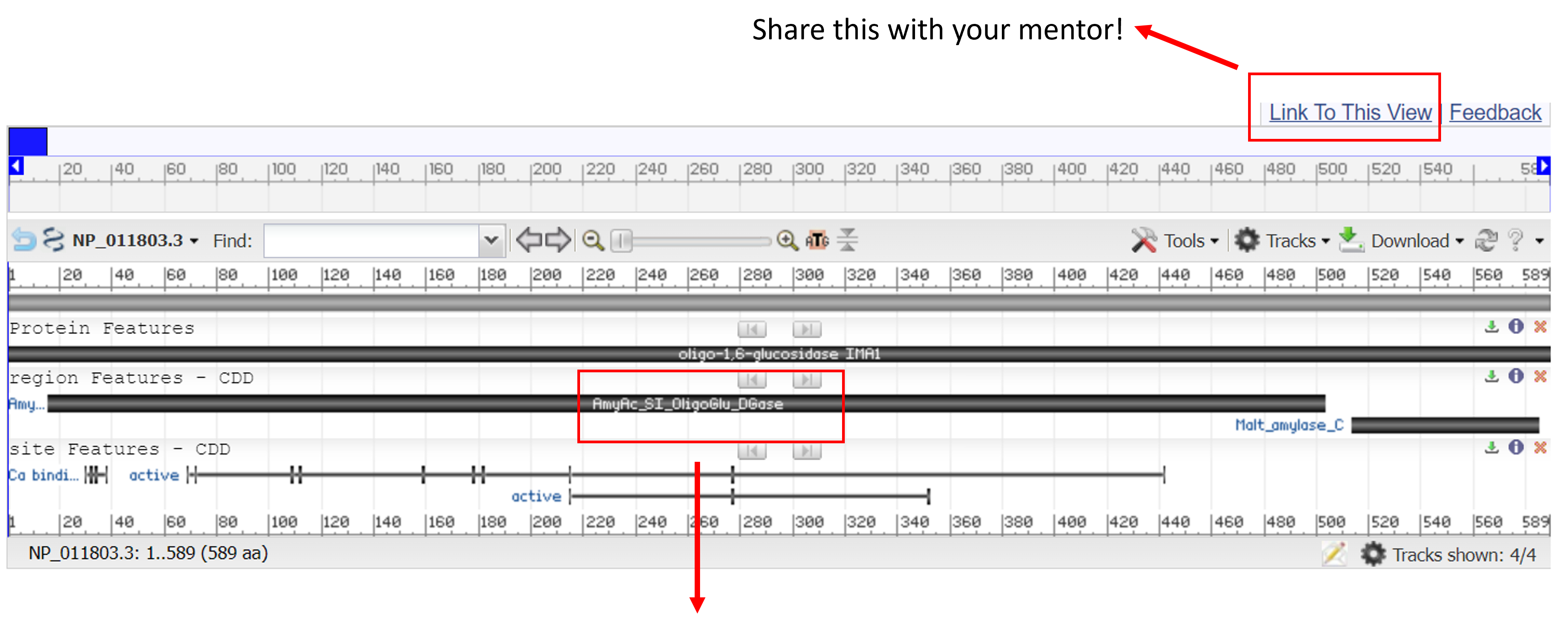
Once again, this is a looooong page with a lot of information so we will highlight one particular feature of Protein records - the Graphics View. Click "Graphics" to view the protein and annotation information in a Sequence Viewer alignment.
Once looking at this view there are a couple of things to point out:
- Many of the options (such as zoom-to-sequence) should be familiar from looking at other NCBI Viewers today.
- Link to this view: Generaes a copy-and-pasteable link directly to this view that you can send to colleagues
- Protein Features Track: Visualizes the actual span of the protein that we are viewing
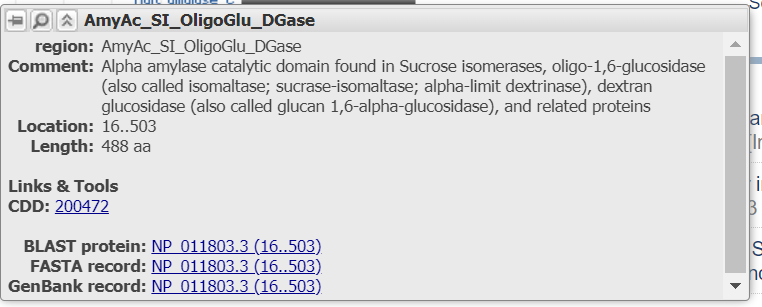
- Region Features: Visualizes span of sub-features relative to the whole protein. In this case, there is a CDD (Conserved Domain Database) feature. Hover over this track to learn more about the protein domain and its function.
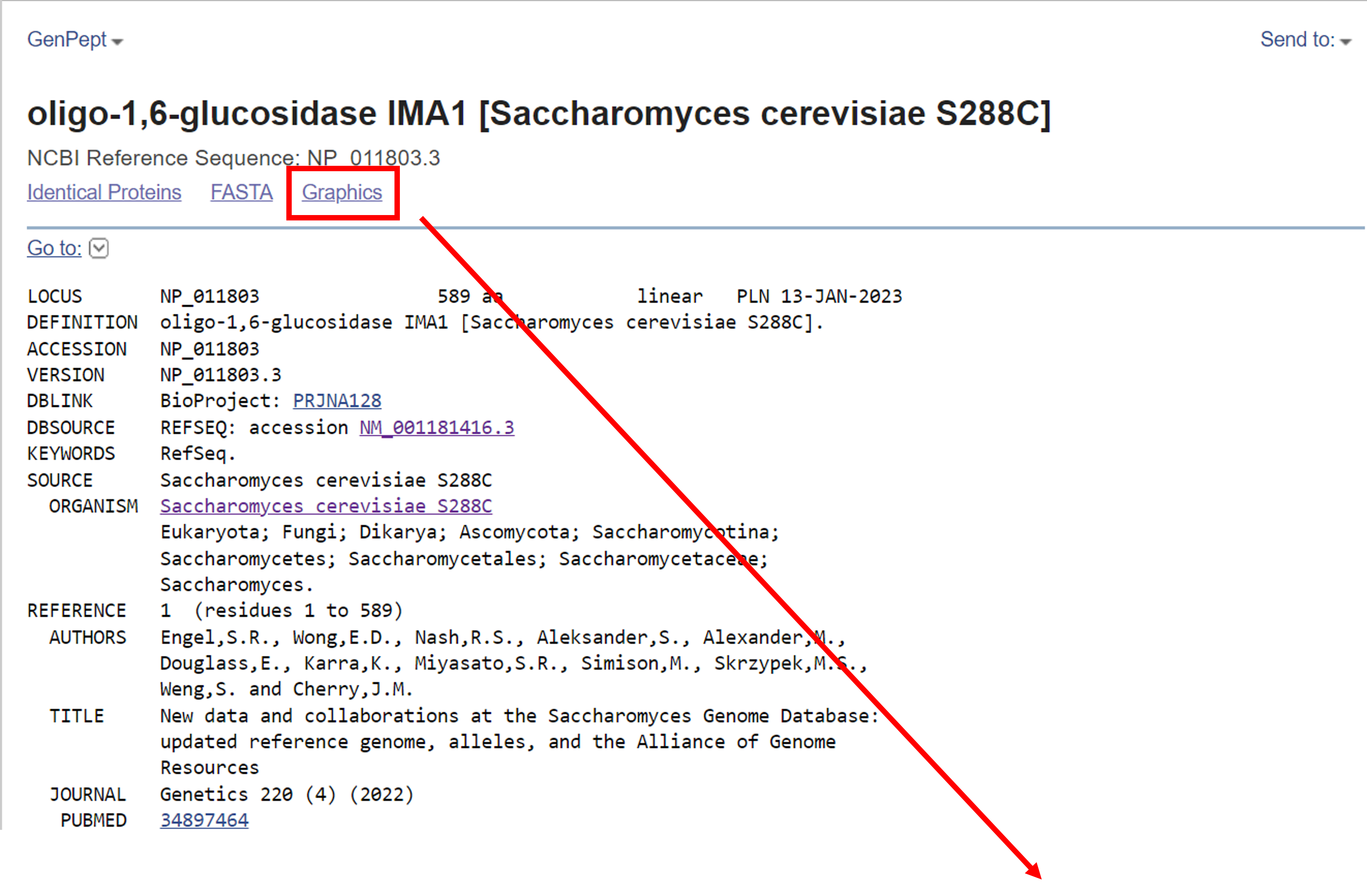
If you want to go back to the original protein record page, you can click on `GenPept` or in most cases, pressing the back button on your browser will do the trick. Now that we have found a protein record and sequence of interest, we are ready for the next step - running BLAST!
Step 4 Conclusions
In this exercise we have accomplished:
- Querying the Gene Database to find info about a target gene
- Identifying relevant parts of a Gene reports page
- Navigating from a Gene page to a Gene Product (protein) record
- Visually examining annotations for this gene product via the Graphics view on a Protein record page
- Preparing to compare IMA1 protein sequences in different yeast strains:

Last Reviewed: June 25, 2023